So, after waiting anxiously for a few days, it’s finally in. The box it arrived in was rather large, but really light. I was worried that there was nothing in it:
After opening it up, I can see that the real board is inside a much smaller box:

And finally taking out of the box:

So, time to roll up our sleeves! I installed Vivado 2016.2 with the free Webpack edition. Compared to the normal System Design edition it is mostly the same, but restricted to only a few devices. Thankfully for me, this Zybo board is one of the free devices supported by the free edition.
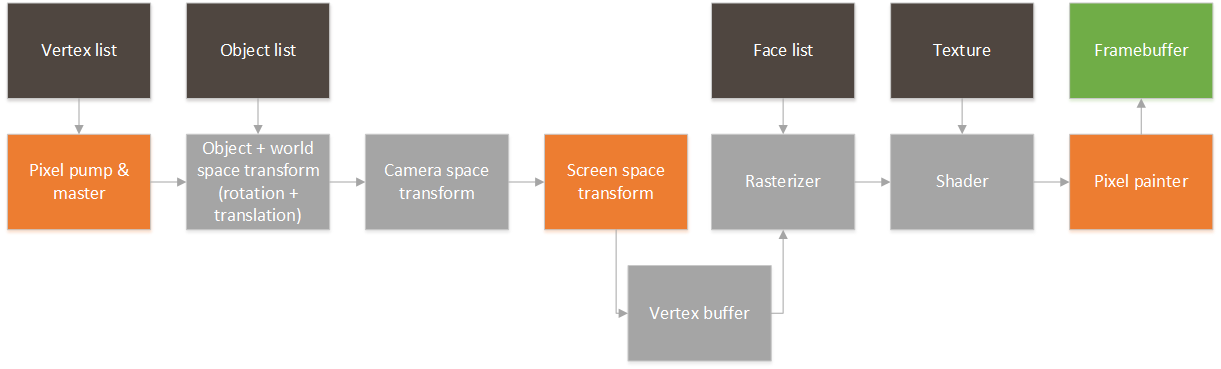
So, first thing first. I need to start creating a project that pumps out an image from a buffer in DDR to a display. Remember the block diagram from last post? We’ll focus on this for now:
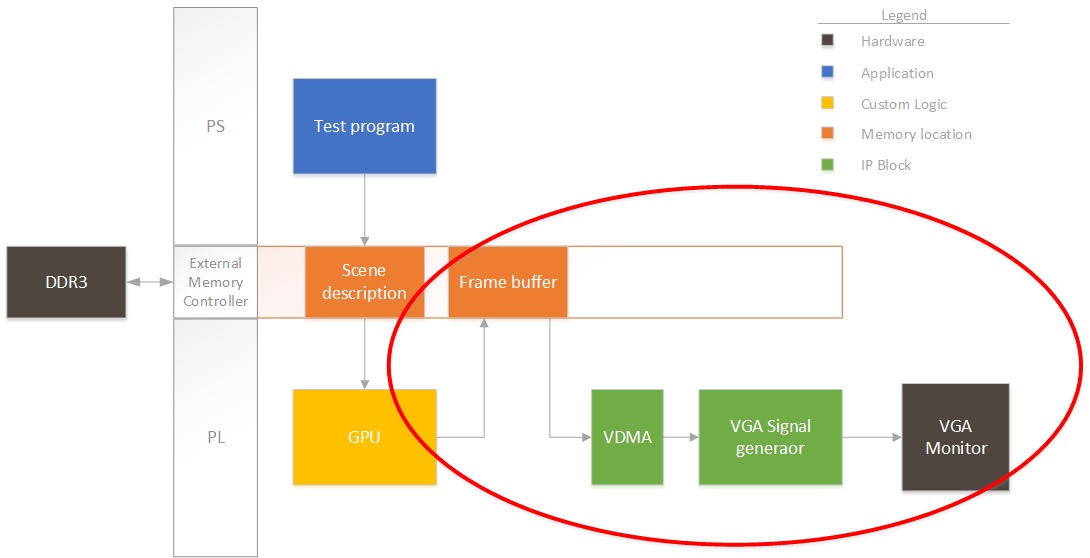
Right now we won’t have any fancy GPU rendering the image, so I’ll have the ARM on the Zynq draw some pixels to see that it’s working properly. So, for this design, I instantiate the PS section in Vivado and add three clocks to the system:
- AXI clock. I will use this for all the AXI-Lite interfaces to control registers, etc.I set this to 50MHz. Could be slower, but seems like a good starting value.
- Memory clock. I will use this to connect all the VDMAs and interfaces that need to talk to memory. I set this to 166MHz. Don’t ask why, but this always seems to work in all my designs.
- Video clock. This will be the pixel clock. Video interfaces will be connected at this speed. (40MHz). I chose this speed since I will be generating an output VESA 800×600 image stream at 60fps.
After adding in the clocks (generated by the PS section for simplicity), I also added a VDMA. This needs to be connected through an AXI protocol converter, since the PS block only supports AXI3, but everything else is AXI4. This first VDMA will pull data from the framebuffer into the logic. I then connected the VDMA to an output AXI to video out block. This block can directly drive a VGA port. The output video block requires some timing, so we also add a timing generator. The timing generator will run in master mode, clocking video for an 800×600 resolution.
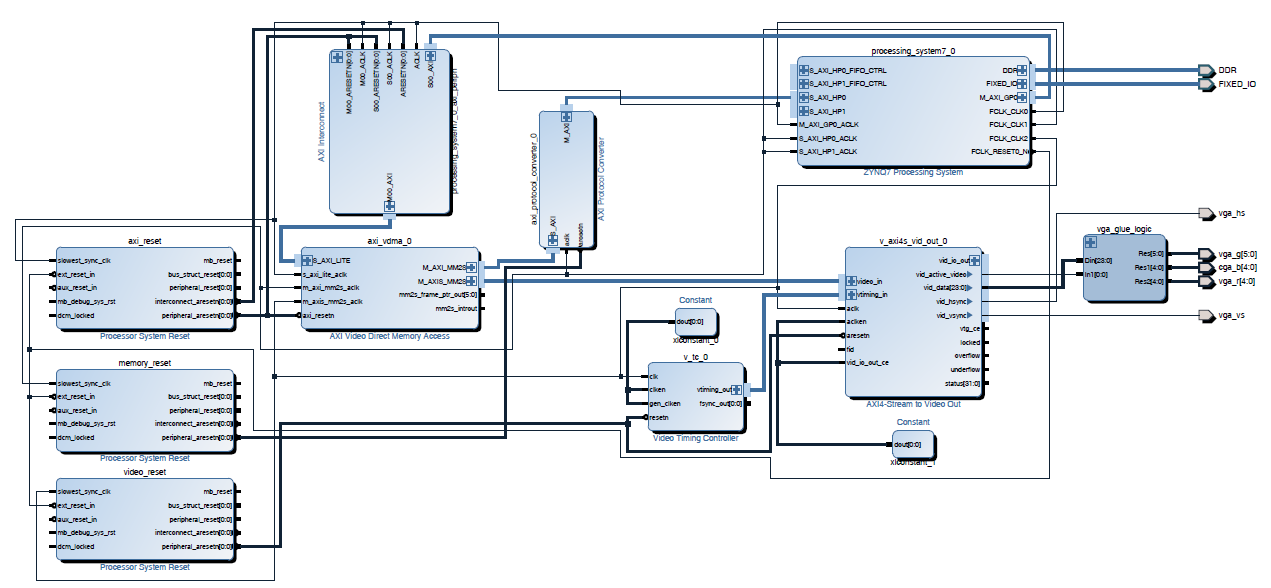
Click on the image to expand it in case (most likely) things are squished in the browser. I will be posting the source files at the end of all my posts.
I added the constraints from the master XDC file on the Digilent website for the VGA port only. The next step is to run full synthesis/route/bitstream generation and see if we have something that is not broken. If that’s good then we’ll program the FPGA and start working on the ARM code that will configure the VDMA and write a test frame. Note that I’m uploading the design files as I’m working so things might be broken.
Goodies:
Vivado block design
Project XDC files
Time to run synthesis, see you next time!